
머신러닝을 공부하다 보면 랜덤포레스트(Random Forest)라는 말을 자주 듣게 됩니다.
이름만 보면 조금 어렵게 느껴집니다.
“랜덤은 무작위라는 뜻이고, 포레스트는 숲이라는 뜻인데, 머신러닝에서 숲이 왜 나올까?”
처음에는 이렇게 느낄 수 있습니다.
하지만 랜덤포레스트의 핵심 개념은 생각보다 쉽습니다.
간단히 말하면 랜덤포레스트는 여러 개의 결정트리가 함께 의견을 내고, 그 의견을 모아서 최종 결정을 내리는 머신러닝 방법입니다.
초등학생도 이해할 수 있게 비유하면 이렇습니다.
한 명의 친구에게만 물어보는 것이 아니라, 여러 친구에게 물어본 뒤 다수결로 결정하는 방법입니다.
한 명이 판단하면 틀릴 수 있습니다.
하지만 여러 명이 각자 생각하고, 그 결과를 모으면 더 안정적인 답을 낼 수 있습니다.
랜덤포레스트도 똑같습니다.
하나의 나무가 아니라, 여러 나무가 함께 판단합니다.
그래서 이름도 랜덤포레스트, 즉 무작위 숲입니다.
1. 먼저 결정트리부터 이해해보자
랜덤포레스트를 이해하려면 먼저 결정트리(Decision Tree)를 알아야 합니다.
결정트리는 말 그대로 결정을 내리는 나무입니다.
질문을 하나씩 따라가다 보면 마지막에 답이 나오는 구조입니다.
예를 들어 동물을 맞히는 문제를 생각해보겠습니다.
“털이 있나요?”
“다리가 4개인가요?”
“날개가 있나요?”
이런 질문을 차례대로 하다 보면 강아지, 토끼, 새, 물고기 같은 답을 찾을 수 있습니다.
위 그림처럼 결정트리는 질문을 따라 내려갑니다.
예를 들어 이런 식입니다.

├─ 예 → 다리가 4개인가요?
│ ├─ 예 → 강아지
│ └─ 아니오 → 토끼
└─ 아니오 → 날개가 있나요?
├─ 예 → 새
└─ 아니오 → 물고기
질문이 나뭇가지처럼 갈라지기 때문에 트리(Tree)라고 부릅니다.
결정트리는 이해하기 쉽다는 장점이 있습니다.
질문을 따라가면 왜 그런 답이 나왔는지 어느 정도 알 수 있기 때문입니다.
하지만 결정트리 하나만 사용하면 문제가 생길 수 있습니다.
하나의 나무가 너무 자기 생각만 강하게 가질 수 있습니다.
또는 학습한 데이터에만 너무 잘 맞고, 새로운 데이터에는 약할 수 있습니다.
그래서 여러 결정트리를 모아서 더 안정적인 결과를 만들자는 생각이 나오게 됩니다.
그것이 바로 랜덤포레스트입니다.
2. 랜덤포레스트는 결정트리 여러 개가 모인 숲이다
랜덤포레스트는 하나의 결정트리가 아닙니다.
여러 개의 결정트리를 만듭니다.
그리고 각각의 결정트리가 따로 판단합니다.
예를 들어 어떤 사진이 고양이인지 강아지인지 맞히는 문제가 있다고 해보겠습니다.
2번 나무: 고양이
3번 나무: 강아지
4번 나무: 고양이
5번 나무: 고양이
이 경우 고양이라고 말한 나무가 더 많습니다.
그래서 랜덤포레스트는 최종 답을 고양이로 정합니다.
이처럼 여러 나무의 의견을 모아서 최종 결정을 내리는 것이 랜덤포레스트의 기본 원리입니다.
분류 문제에서는 보통 다수결 투표를 합니다.
예를 들어 고양이냐 강아지냐, 합격이냐 불합격이냐, 스팸 메일이냐 아니냐 같은 문제입니다.
반대로 숫자를 예측하는 문제에서는 보통 평균값을 사용합니다.
예를 들어 집값을 예측한다고 해보겠습니다.
2번 나무 예측: 3억 2천만 원
3번 나무 예측: 2억 8천만 원
이런 식으로 여러 나무가 예측한 값을 평균 내서 최종 예측값을 정합니다.
3. 앙상블이란?
랜덤포레스트를 이해할 때 꼭 알아야 하는 용어가 있습니다.
바로 앙상블(Ensemble)입니다.
앙상블은 원래 음악에서 많이 쓰는 말입니다.
피아노 혼자 연주하는 것도 좋지만, 피아노, 바이올린, 첼로, 플루트가 함께 연주하면 더 풍성한 음악이 됩니다.
머신러닝에서도 비슷합니다.
여러 개의 모델을 함께 사용해서 더 좋은 결과를 만드는 방법을 앙상블이라고 합니다.
랜덤포레스트는 여러 개의 결정트리를 함께 사용합니다.
그래서 랜덤포레스트는 대표적인 앙상블 모델입니다.
한 명의 친구보다 여러 친구의 의견을 듣는 것이 더 안정적일 때가 있습니다.
한 명의 전문가보다 여러 전문가의 의견을 모으면 더 균형 잡힌 판단을 할 수 있습니다.
랜덤포레스트도 마찬가지입니다.
하나의 결정트리가 실수하더라도 다른 결정트리들이 그 실수를 보완할 수 있습니다.
4. 배깅이란?
랜덤포레스트에서 또 중요한 용어가 배깅(Bagging)입니다.
배깅은 쉽게 말하면 다음과 같습니다.
데이터를 여러 번 랜덤하게 뽑아서 여러 모델에게 따로 공부시키는 방법입니다.
조금 더 쉽게 설명해보겠습니다.
반에 학생이 5명 있다고 해보겠습니다.
선생님이 모든 학생에게 완전히 똑같은 문제지를 나눠주면, 학생들의 생각이 비슷해질 수 있습니다.
하지만 조금씩 다른 문제지를 나눠주면 어떻게 될까요?
학생마다 보는 문제가 조금씩 다릅니다.
그래서 각자 다른 방식으로 공부하고, 다른 답을 낼 수 있습니다.
마지막에는 학생들의 답을 모아서 최종 답을 정합니다.
이것이 배깅의 느낌입니다.

위 그림을 보면 전체 데이터가 있고, 각 나무가 조금씩 다른 데이터를 받아서 공부합니다.
그리고 각 나무가 답을 냅니다.
마지막에는 모든 답을 모아서 투표합니다.
이 과정을 통해 하나의 나무만 사용할 때보다 더 안정적인 결과를 만들 수 있습니다.
정리하면 이렇습니다.
배깅: 데이터를 랜덤하게 여러 번 뽑아 여러 모델을 학습시키는 방법
랜덤포레스트: 배깅을 이용해 여러 결정트리를 만든 앙상블 모델
5. 랜덤포레스트에서 “랜덤”은 무엇이 랜덤일까?
랜덤포레스트에는 이름 그대로 랜덤, 즉 무작위 요소가 들어갑니다.
크게 두 가지가 랜덤입니다.
첫 번째는 데이터를 랜덤으로 뽑는 것입니다.
모든 결정트리가 완전히 같은 데이터를 보고 공부하지 않습니다.
각각의 나무가 조금씩 다른 데이터를 보고 공부합니다.
두 번째는 질문에 사용할 특징을 랜덤으로 고르는 것입니다.
예를 들어 과일을 구분한다고 해보겠습니다.
사용할 수 있는 특징은 여러 가지입니다.
크기
무게
향기
껍질 모양
당도
결정트리는 이 특징들을 보고 질문을 만듭니다.
하지만 랜덤포레스트에서는 모든 나무가 매번 똑같은 특징만 보지 않습니다.
나무마다 일부 특징을 랜덤하게 보고 판단합니다.
이렇게 하면 모든 나무가 너무 비슷해지는 것을 막을 수 있습니다.
즉, 랜덤포레스트는 여러 나무가 서로 조금씩 다른 관점으로 문제를 바라보게 만듭니다.
그래서 더 다양한 의견을 모을 수 있습니다.
6. n_estimators란?
랜덤포레스트를 실제 코드로 사용하다 보면 n_estimators라는 설정을 자주 보게 됩니다.
처음 보면 낯선 단어입니다.
하지만 뜻은 간단합니다.
n_estimators는 랜덤포레스트 안에 들어가는 결정트리의 개수입니다.
예를 들어 n_estimators=100이라고 하면 결정트리 100개를 만들겠다는 뜻입니다.
이 코드는 이렇게 이해하면 됩니다.
“나무 100개로 이루어진 랜덤포레스트를 만들겠다.”
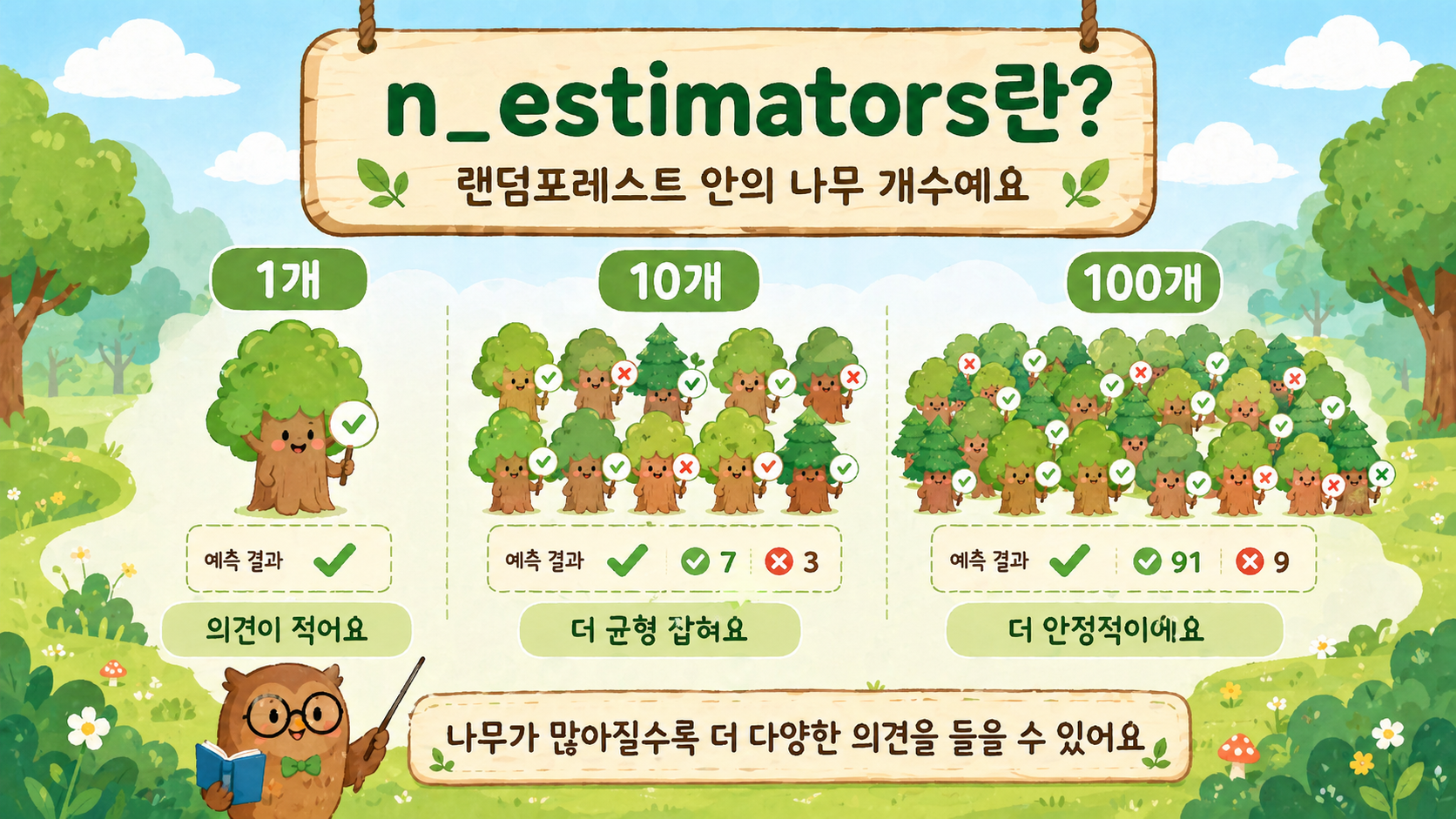
나무가 1개만 있으면 한 명의 의견만 듣는 것과 비슷합니다.
나무가 10개 있으면 조금 더 다양한 의견을 들을 수 있습니다.
나무가 100개 있으면 더 많은 의견을 모을 수 있습니다.
하지만 무조건 많다고 좋은 것은 아닙니다.
나무가 많아질수록 계산 시간이 오래 걸립니다.
컴퓨터가 더 많은 나무를 만들고, 더 많은 예측을 계산해야 하기 때문입니다.
그래서 보통 처음에는 이런 값들을 많이 사용합니다.
n_estimators=200
n_estimators=500
처음 공부할 때는 n_estimators=100 정도로 시작하면 이해하기 쉽습니다.
7. 가지치기란?
이번에는 가지치기(Pruning)를 알아보겠습니다.
가지치기는 실제 나무에서도 사용하는 말입니다.
나무가 너무 복잡하게 자라면 불필요한 가지를 잘라내서 깔끔하게 정리합니다.
결정트리에서도 비슷합니다.
결정트리가 너무 깊고 복잡해지면 훈련 데이터는 아주 잘 맞힐 수 있습니다.
하지만 새로운 데이터가 들어오면 오히려 잘 못 맞힐 수 있습니다.
이것을 과적합(Overfitting)이라고 합니다.
쉽게 말하면, 문제의 원리를 이해한 것이 아니라 답만 외운 상태와 비슷합니다.
예를 들어 학생이 수학 개념을 이해하지 않고 문제집 답만 외웠다고 해보겠습니다.
똑같은 문제가 나오면 맞힐 수 있습니다.
하지만 숫자나 상황이 조금만 바뀌면 틀릴 수 있습니다.
결정트리도 마찬가지입니다.
학습 데이터에만 너무 딱 맞게 자라면 새로운 데이터에 약해질 수 있습니다.
그래서 너무 복잡한 가지를 줄이고 핵심만 남기는 것이 가지치기입니다.
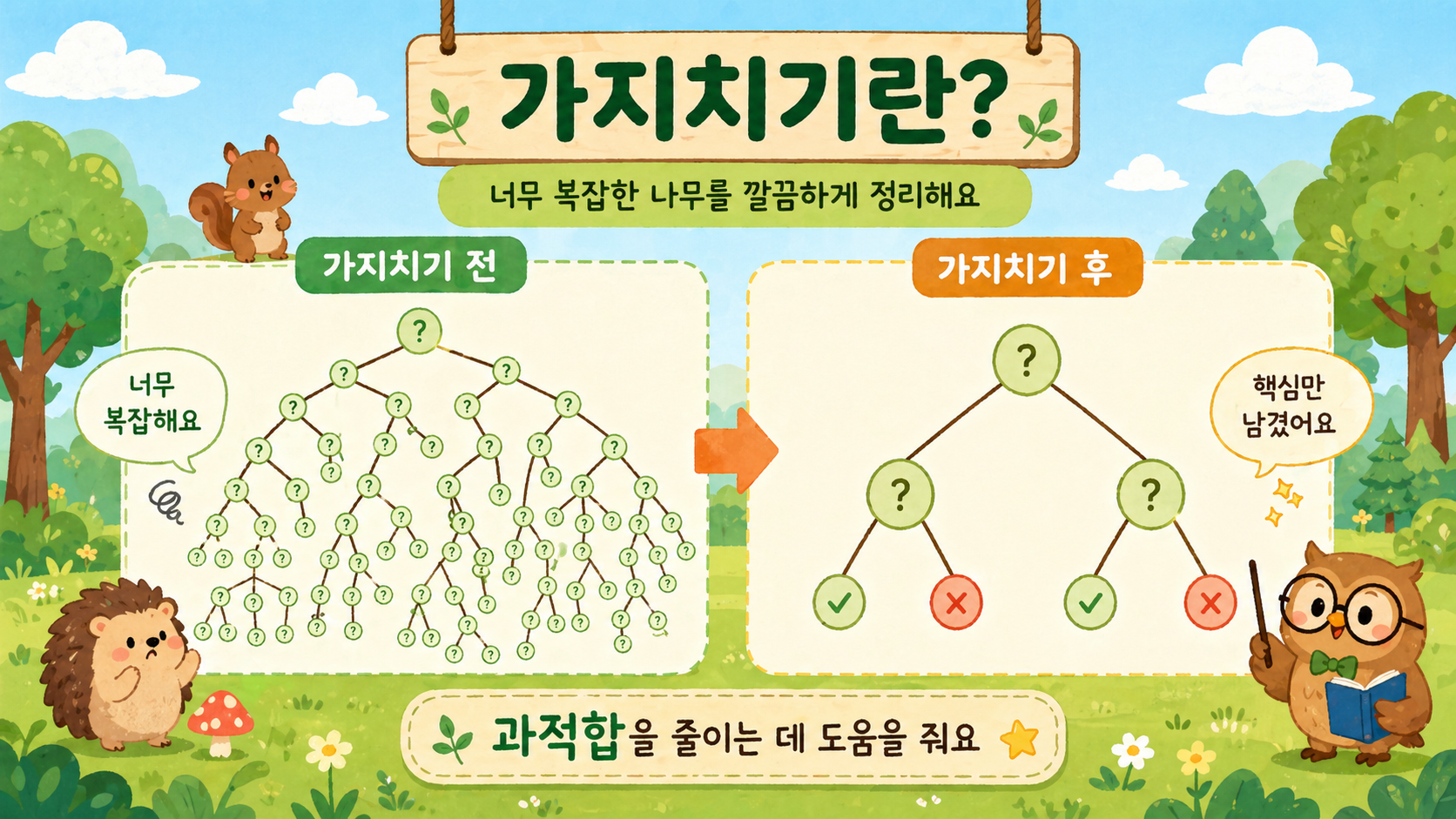
위 그림처럼 가지치기 전에는 나무가 너무 복잡합니다.
질문이 너무 많고, 가지가 너무 많습니다.
하지만 가지치기 후에는 핵심 질문만 남습니다.
이렇게 하면 과적합을 줄이는 데 도움이 됩니다.
랜덤포레스트에서는 여러 트리를 함께 사용하기 때문에 결정트리 하나보다 과적합에 강한 편입니다.
하지만 그래도 트리가 너무 복잡해지지 않도록 여러 설정을 조절할 수 있습니다.
대표적으로 이런 설정들이 있습니다.
min_samples_split
min_samples_leaf
여기서 max_depth는 트리가 너무 깊게 자라지 않도록 제한하는 값입니다.
예를 들어 max_depth=5라고 하면 트리의 깊이를 5단계 정도로 제한하겠다는 뜻입니다.
8. 랜덤포레스트의 장점
랜덤포레스트는 실무에서도 많이 쓰이는 머신러닝 알고리즘입니다.
이유는 장점이 꽤 많기 때문입니다.
첫 번째 장점은 성능이 안정적이라는 점입니다.
하나의 결정트리만 사용하면 특정 데이터에 너무 치우칠 수 있습니다.
하지만 랜덤포레스트는 여러 결정트리의 의견을 모으기 때문에 더 안정적인 판단을 할 수 있습니다.
두 번째 장점은 과적합에 비교적 강하다는 점입니다.
여러 나무가 서로 다른 데이터를 보고 공부하기 때문에 하나의 나무가 잘못된 방향으로 판단해도 전체 결과가 크게 흔들리지 않을 수 있습니다.
세 번째 장점은 분류와 회귀 모두에 사용할 수 있다는 점입니다.
분류는 종류를 맞히는 문제입니다.
고양이인가 강아지인가?
합격인가 불합격인가?
회귀는 숫자를 예측하는 문제입니다.
내일 온도는 몇 도일까?
상품 판매량은 얼마나 될까?
랜덤포레스트는 이런 문제들에 모두 사용할 수 있습니다.
네 번째 장점은 어떤 특징이 중요한지 확인할 수 있다는 점입니다.
예를 들어 집값을 예측할 때 어떤 요소가 중요했는지 확인할 수 있습니다.
면적
방 개수
층수
건축 연도
이 중 어떤 특징이 예측에 더 많이 영향을 줬는지 볼 수 있습니다.
이것을 보통 특성 중요도(Feature Importance)라고 합니다.
9. 랜덤포레스트의 단점
물론 랜덤포레스트도 완벽한 알고리즘은 아닙니다.
단점도 있습니다.
첫 번째 단점은 계산 시간이 늘어날 수 있다는 점입니다.
결정트리 하나만 만드는 것보다 결정트리 100개, 200개를 만드는 것이 더 오래 걸립니다.
그래서 데이터가 아주 크거나 빠른 응답이 필요한 서비스에서는 조정이 필요합니다.
두 번째 단점은 결과를 설명하기가 조금 어려울 수 있다는 점입니다.
결정트리 하나는 질문 흐름을 따라가면 이해하기 쉽습니다.
하지만 랜덤포레스트는 수많은 결정트리의 결과를 합칩니다.
그래서 전체 판단 과정을 한눈에 설명하기는 어렵습니다.
세 번째 단점은 모델 크기가 커질 수 있다는 점입니다.
n_estimators 값을 크게 하면 나무가 많아집니다.
나무가 많아지면 모델도 커지고, 예측 시간도 늘어날 수 있습니다.
10. 주요 용어 한 번에 정리하기
| 결정트리 | 질문을 따라가며 답을 찾는 나무 구조 |
| 랜덤포레스트 | 여러 결정트리를 모아 만든 머신러닝 모델 |
| 앙상블 | 여러 모델의 힘을 합쳐 더 좋은 결과를 만드는 방법 |
| 배깅 | 데이터를 랜덤하게 여러 번 뽑아 여러 모델을 학습시키는 방법 |
| 가지치기 | 너무 복잡한 트리의 불필요한 가지를 줄이는 방법 |
| n_estimators | 랜덤포레스트 안에 들어가는 결정트리 개수 |
| 과적합 | 학습 데이터는 잘 맞히지만 새로운 데이터에는 약한 상태 |
| max_depth | 결정트리가 얼마나 깊게 자랄 수 있는지 정하는 값 |
11. 간단한 파이썬 코드로 보기
파이썬에서는 scikit-learn 라이브러리를 사용하면 랜덤포레스트를 쉽게 만들 수 있습니다.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(
n_estimators=100,
max_depth=5,
random_state=42
)
model.fit(X_train, y_train)
pred = model.predict(X_test)여기서 중요한 부분은 다음과 같습니다.
n_estimators=100결정트리 100개를 사용하겠다는 뜻입니다.
max_depth=5각 결정트리가 너무 깊게 자라지 않도록 제한한다는 뜻입니다.
random_state=42랜덤하게 뽑는 과정을 고정해서, 다시 실행해도 같은 결과가 나오도록 하는 설정입니다.
처음 공부할 때는 이 정도만 이해해도 충분합니다.
12. 랜덤포레스트를 한 문장으로 정리하면?
랜덤포레스트는 이렇게 정리할 수 있습니다.
여러 개의 결정트리를 만들고, 각각의 의견을 모아서 더 안정적인 결정을 내리는 머신러닝 방법입니다.
초등학생식으로 더 쉽게 말하면 이렇게 말할 수 있습니다.
한 명에게만 물어보지 않고, 여러 명에게 물어본 다음 다수결로 정하는 똑똑한 방법입니다.
랜덤포레스트는 이름은 어렵지만, 핵심은 단순합니다.
나무 하나보다 숲이 더 튼튼하듯이, 모델 하나보다 여러 모델이 함께 판단하면 더 안정적인 결과를 만들 수 있습니다.
마무리
랜덤포레스트는 머신러닝을 처음 공부할 때 꼭 알아두면 좋은 알고리즘입니다.
결정트리, 앙상블, 배깅, 가지치기, n_estimators 같은 용어가 처음에는 어렵게 느껴질 수 있습니다.
하지만 숲속의 여러 나무가 함께 의견을 내고 투표한다고 생각하면 훨씬 쉽게 이해할 수 있습니다.
정리하면 다음과 같습니다.
랜덤포레스트 = 여러 결정트리가 모인 숲
앙상블 = 여러 모델의 힘을 합치는 방법
배깅 = 데이터를 랜덤하게 나눠 여러 모델을 학습시키는 방법
n_estimators = 숲 안에 있는 나무의 개수
가지치기 = 너무 복잡한 나무를 깔끔하게 정리하는 방법
랜덤포레스트를 이해하면 머신러닝의 중요한 흐름 하나를 잡을 수 있습니다.
바로 하나의 모델에만 의존하지 않고, 여러 모델의 의견을 모아 더 좋은 결정을 내리는 방식입니다.
이 개념은 랜덤포레스트뿐만 아니라 다른 여러 머신러닝 기법을 이해하는 데도 큰 도움이 됩니다.
'AI > 머신러닝' 카테고리의 다른 글
| 숫자의 함정에서 벗어나는 법: 스케일링(Scaling)과 로그(Log) 변환 (0) | 2026.04.28 |
|---|